上分宝:值得大家信赖的下载网站!
时间:2025-04-15 17:42:25来源:互联网
通过OEX官方下载入口,您不仅能够下载到最新、最稳定的软件版本,还能享受到官方提供的安全保障和技术支持,确保您的数字资产安全无忧。遵循官方指南,轻松几步即可完成下载与安装,让您随时随地掌握市场动态,高效管理您的加密货币资产。

该平台整合了初学者与专业用户的使用需求,为新手用户提供了一套完整的流程引导,确保他们能够零负担入门并迅速上手。在内置的学院模块中,用户可以学习到如何购买数字货币、进行数字货币交易,以及掌握专业的交易策略。此外,用户还能深入了解丰富的数字货币知识和前沿的区块链行业研究报告,助力新手秒变数字货币达人。同时,平台提供实时数据推送功能,用户只需一键设置价格警示,即可随时获取所关注加密货币的价格变化;还能实时查看比特币现货、期货、期权价格,实现移动式数字资产管理。
一、下载:
1、直接在本站访问OEX官方网站下载找到对应的安卓安装包。
2、点击下载安装,安装完成后,打开应用程序。
二、注册登录:
1、打开OEX官方,点击页面上方【立即登录/注册】,进入注册页面;
2、注册时您需要同时绑定手机号和邮箱。
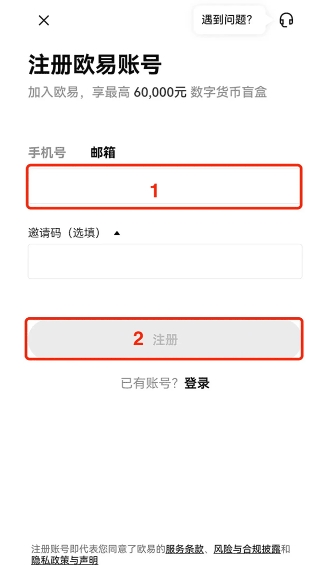
3、按要求选择【居住国家/地区】,点击【确认】
4、设置【登录密码】—点击【下一步】,按要求完成注册即可。在交易前,需要完成KYC认证!
5、个人信息设置:进行买/卖币交易前需要您先完成身份认证和绑定收付款方式。
三、KYC认证
1、进入KYC认证界面:
登录后,进入个人中心。
在个人中心菜单中找到并点击“身份认证”或类似的选项,开始认证流程。
2、提交个人信息与证件:
按照提示填写姓名、国籍、出生日期、身份证件类型(如护照、身份证)等基本信息。
清晰拍摄或扫描您的有效身份证件正反面照片,并上传至指定位置。请确保图片质量清晰,文字无遮挡,符合尺寸和文件格式要求(通常支持jpg/jpeg/png格式,大小不超过10MB)。
3、完成认证:
提交所有必要信息后,耐心等待审核。一般情况下,审核会在较短时间内完成。
审核通过后,您将收到相关通知,此时您的账户已完成KYC认证,可以享受到更高级别的交易权限和服务。
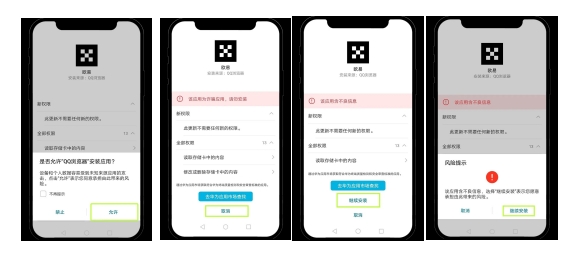
下载后无法安装怎么办?
一些安卓手机在下载OEX官方安装包后,可能会遇到“安全风险”、“病毒风险”等提示而无法顺利安装。针对这一问题,您可以根据手机品牌和操作系统的不同,采取以下相应措施以完成安装:
华为手机(安卓版):
点击“允许继续安装”,并避免将应用移入管控范围,随后按照界面提示的操作步骤即可完成安装。
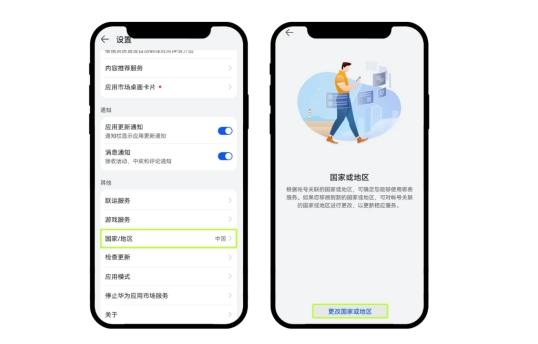
华为手机(鸿蒙版):
进入应用市场,依次点击【我的】、【设置】、选择【国家或地区】,通过更改至其他非中国大陆的国家或地区来解决问题。
小米手机:
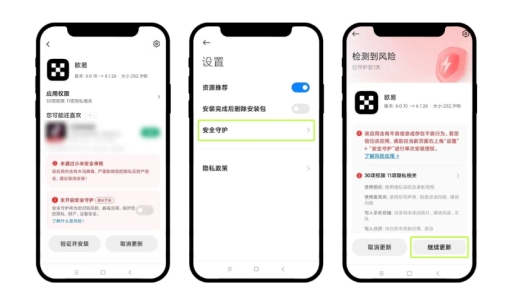
在安装页面时,点击右上角设置按钮,找到并开启【安全守护】。之后返回安装界面,按照提示操作即可成功安装OEX官方。
OPPO 手机:
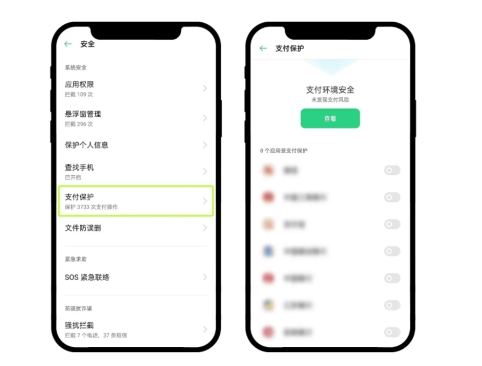
首先打开OPPO手机的设置界面,进入【手机管家】或自带的安全管理应用。然后找到并选择【支付保护】,在此关闭所有软件的保护设置。完成上述步骤后,再尝试下载安装OEX官方,安装成功后请及时恢复之前的保护设置。
其他方法
其他品牌/类型的安卓手机,可以尝试以下方法安装OEX App。
●关闭网络、蓝牙,使用夸克浏览器或手机自带的浏览器下载安装,在设置那里把病毒改成360等;
●设置一【应用和通知】-【权限管理】-【安全和隐私】一【应用锁】一【信任此应用】一再登录,就不再出现“风险”提示。
●下载好了OEX官方安装包,把数据流量都关掉再安装。
1、多重签名钱包:
OEX将用户资产存储在多重签名钱包中,这种钱包技术需要多个私钥共同签名才能完成交易,从而大大提升了资产的安全性。
2、银行级SSL加密技术:
OEX采用银行级别的SSL加密技术,确保交易信息和用户信息在传输过程中的安全性,防止信息被窃取或篡改。
3、两步验证技术:
OEX支持Google Authenticator两步验证技术,用户在登录和进行重要操作时,除了输入账号密码外,还需要提供额外的动态验证码,有效防止了账户被盗用。
4、C2C视频认证:
OEX平台实施了严格的实名认证和视频认证机制,通过视频认证实时验证用户身份,有效防止了身份盗用和虚假交易,保障了用户的权益。
5、24小时安全监控:
OEX平台提供24小时不间断的安全监控,对交易过程进行实时监控,并处理可能的投诉,以确保交易的公平性和可靠性。
6、专业客户服务与支持:
OEX平台设有专业的客户服务与支持团队,帮助用户解决在使用过程中遇到的问题和困难,包括安全相关的问题。
1、开启交易入口并购买
点击手机桌面的【OEX官方应用图标】,打开应用程序。
在 OKX 主页面,找到并点击【买币】按钮,进入买币页面。
在买币页面,选择【C2C 买币】模式。
在搜索栏中,输入目标数字资产名称,如【BTC】或【USDT】。
利用【筛选功能】,从价格区间、交易额度、支付方式等方面筛选委托单,并参考商家信誉评级等信息选择信任的商家。
点击【购买】按钮,开启交易流程。

2、明确购买细节与沟通卖家
在OEX购买详情页面,查看并选择合适的【购买方式】,如按金额或数量购买。
在相应输入框,填入购买【数量】。
仔细核对【订单信息】,包括资产类别、数量、金额、卖家信息等。
查看【付款详情】,了解收款账户信息和支付要求。
通过【平台内置沟通工具】与卖家沟通,确认付款方式和预计到账时间等细节。
3、执行支付流程
按照卖家指示,若选择【银行转账】:
打开银行【手机应用】或登录【网上银行平台】。
在转账页面,核对【收款银行名称】、【账号】、【户名】等信息,确保无误。
输入【转账金额】,选择【转账方式】,完成转账操作。
若使用【电子支付平台】:
打开相应【电子支付应用】,找到【转账】或【付款】入口。
输入【收款方账号或二维码信息】,核对后输入【支付金额】。
根据平台要求,输入【支付密码】、【指纹识别】或【面部识别】等身份验证信息,完成支付。
支付完成后,迅速切换回 OKX 应用,点击【我已支付】按钮。
新手用户若需上传【付款证明】:
按照平台指引,使用手机【相机功能】拍摄清晰完整的付款凭证图片,如银行转账电子回单截图或电子支付平台支付成功页面截图,确保包含关键信息。
将图片上传至平台指定位置。

4、确认资产到账
支付完成后,保持对【OEX应用通知】的关注,同时定期查看【订单状态】。
收到平台提示卖家已确认收款的消息后,在【资产】页面点击【我已确认付款】按钮。
系统将自动跳转至【资金账户】页面,查看所购买数字资产的【到账数量】、【市值估值】、【手续费明细】等信息。

5、交易复盘
交易完成后,在【OEX应用内】对本次交易进行复盘:
回顾【筛选委托单】过程,思考是否有优化空间。
分析【选择商家】的决策依据,总结经验。
反思【确定购买方式和数量】的合理性,考虑改进措施。
回顾【与卖家沟通】情况,总结沟通技巧。
ok交易所:ok比特币交易平台
欧易下载官网,帮助你更好地管理数字资产
oe交易所官方下载:体验便捷交易的入口
欧易c2c视频验证在哪找?轻松查找验证位置与步骤
三大交易所app下载综合对比:畅享安全高效加密交易
oe交易所是骗子吗?从注册到交易,新手指引全攻略
殴易官网交易所:数字货币交易的领航者
oe交易软件下载,最新币交易所app官方版本及下载途径
oex最新版本:解锁数字资产新玩法
P ubg
枪战射击
action对魔忍
动作游戏
2233盒子
其他游戏
oppo助手2.0
其他游戏
pubg mobile国际服
动作游戏
汪汪队救援小镇
益智休闲
touchitrikka
益智休闲
斗罗大陆魂师对决
角色扮演
捉拿西门庆
角色扮演
极乐园
聊天交友
湖北农村商业银行
金融理财
51品茶
交友约会
旋风免费加速器永久免费版
加速工具
极乐园paradise
聊天交友
套路
社交聊天
丝目
社交聊天
七点工具箱
工具应用
酷狗输入法(搜狗输入法)
常用工具